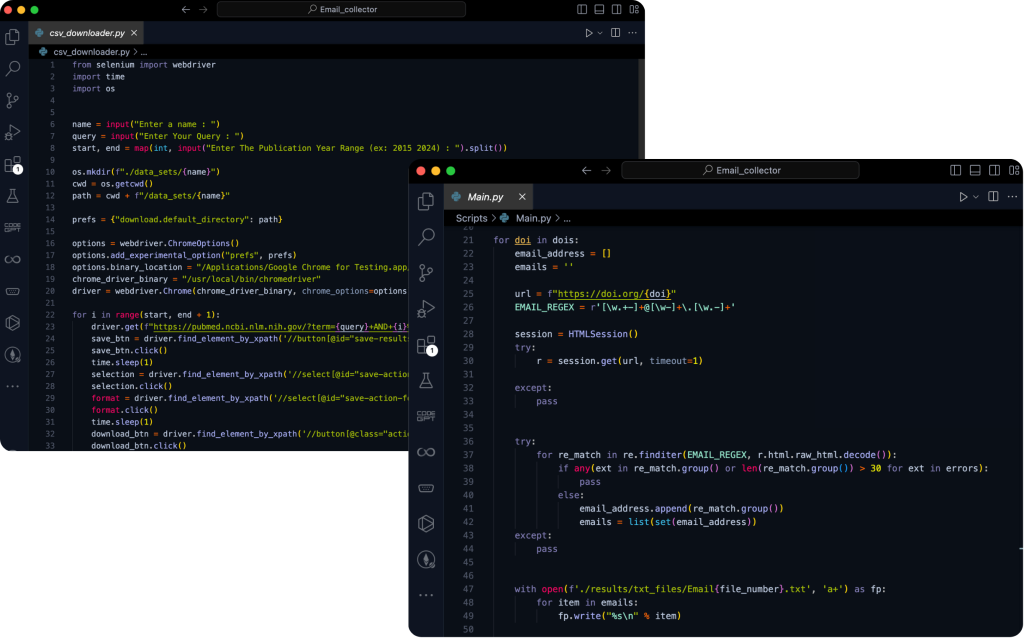
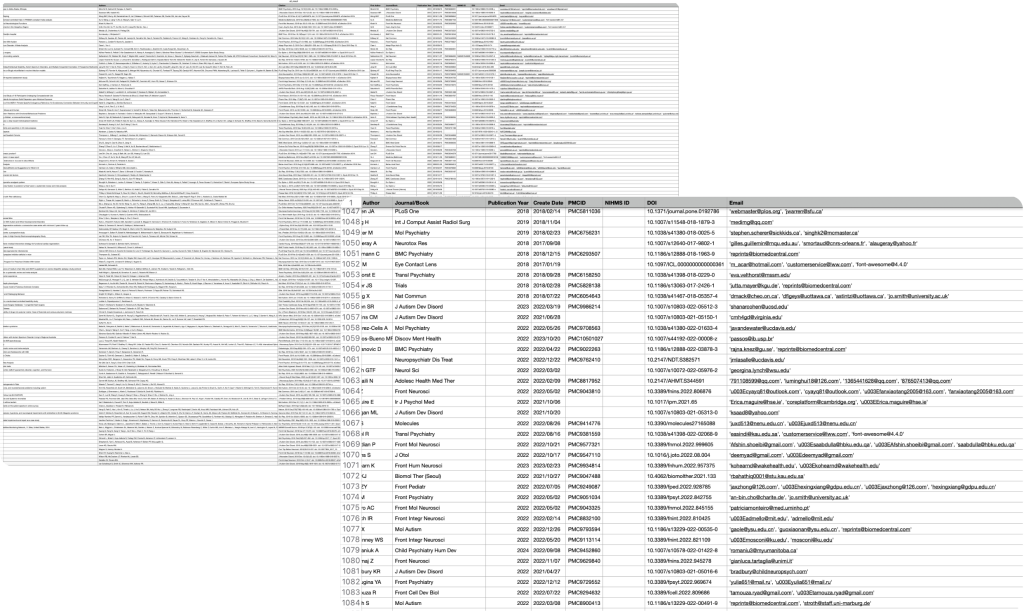
In this project, I developed a Python program to automate the extraction of author emails and additional metadata from scientific papers on PubMed. The program takes user inputs such as search queries and publication date range, downloads raw data in CSV format, and processes each paper’s website using DOI links to extract relevant information. By employing parallel processing, the program optimizes performance, handling large datasets efficiently and outputting cleaned, structured data in a new CSV file. This tool significantly accelerates the process of data extraction, making it a valuable asset for researchers and professionals needing bulk data from PubMed.