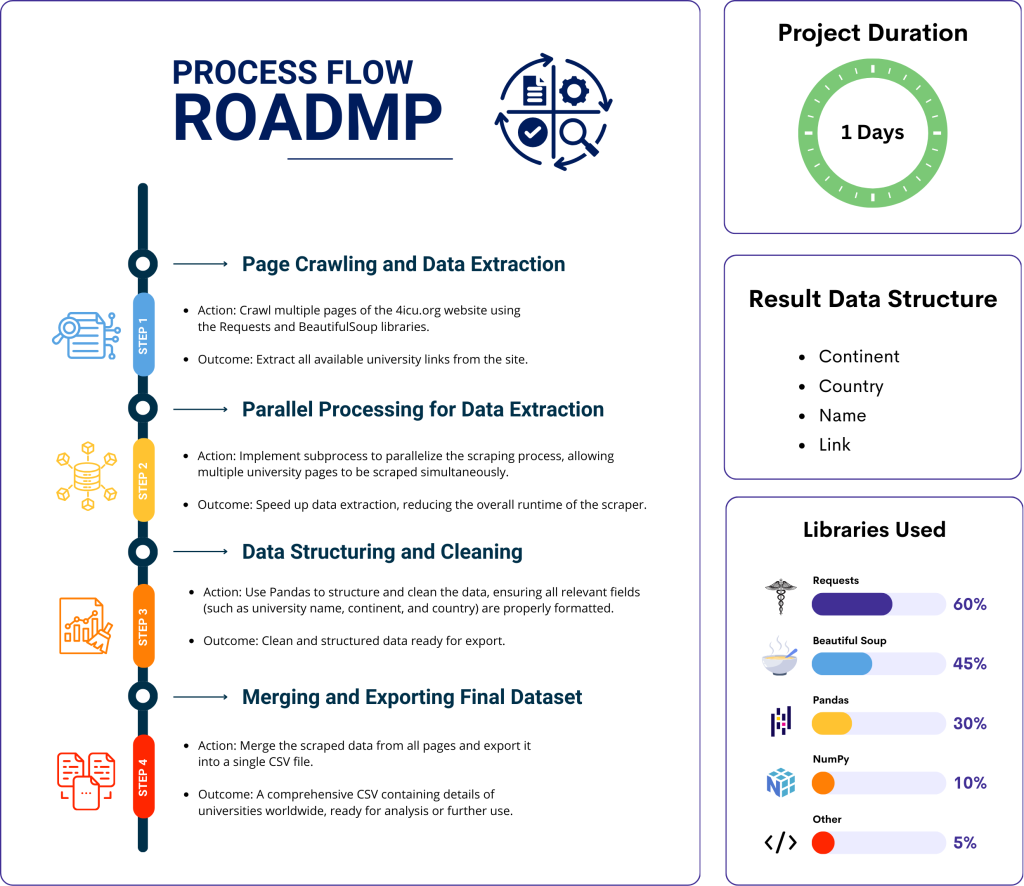
This project automates the extraction of global university data from the 4icu website using Python. By leveraging web scraping techniques, the program gathers key information such as university names, links, countries, and continents, storing the results in structured CSV files. The data is then ready for further analysis or integration into other applications.
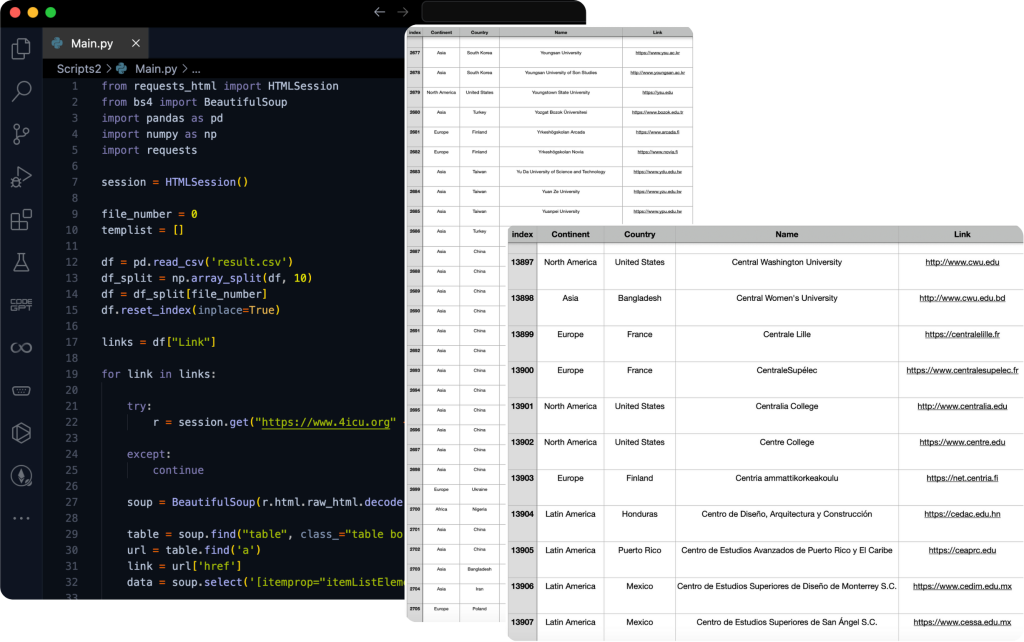
The scraper is implemented using Python, leveraging the Requests library to fetch web pages and BeautifulSoup to parse HTML content. Parallel processing is used to optimize the extraction speed, while Pandas structures the data into a clean, tabular format. The final output is a well-organized CSV file containing university names, links, countries, and continents. Below is a preview of the code in action, along with a sample of the extracted data.