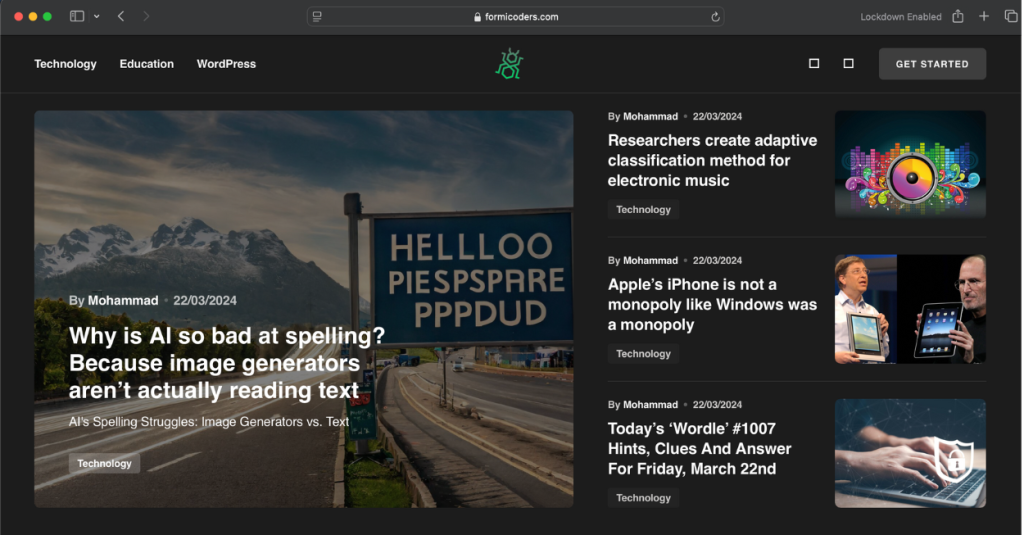
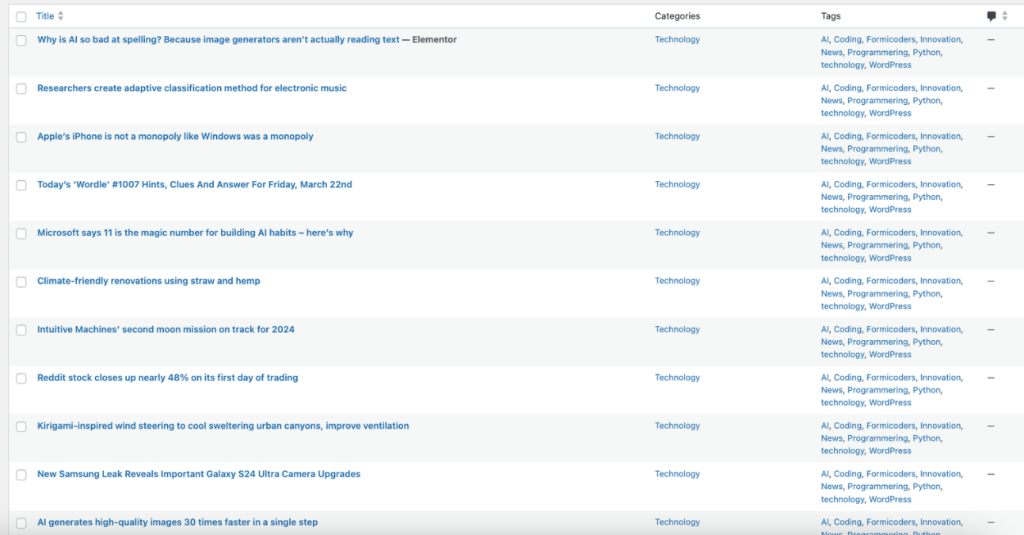
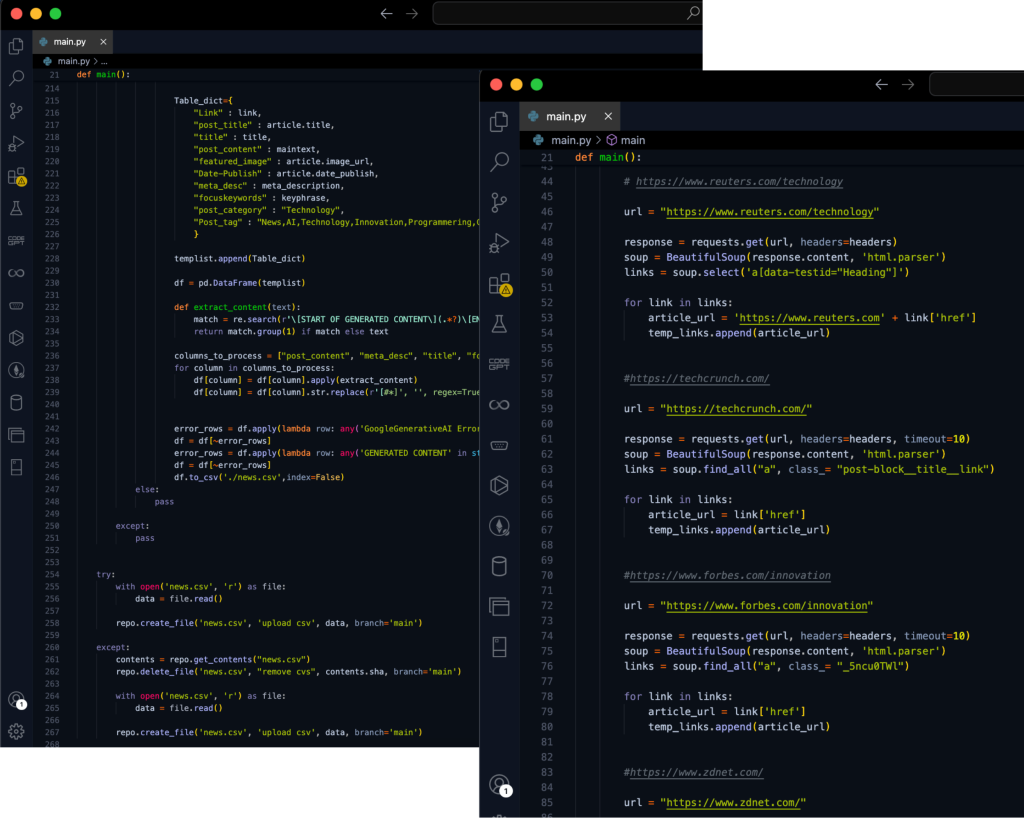
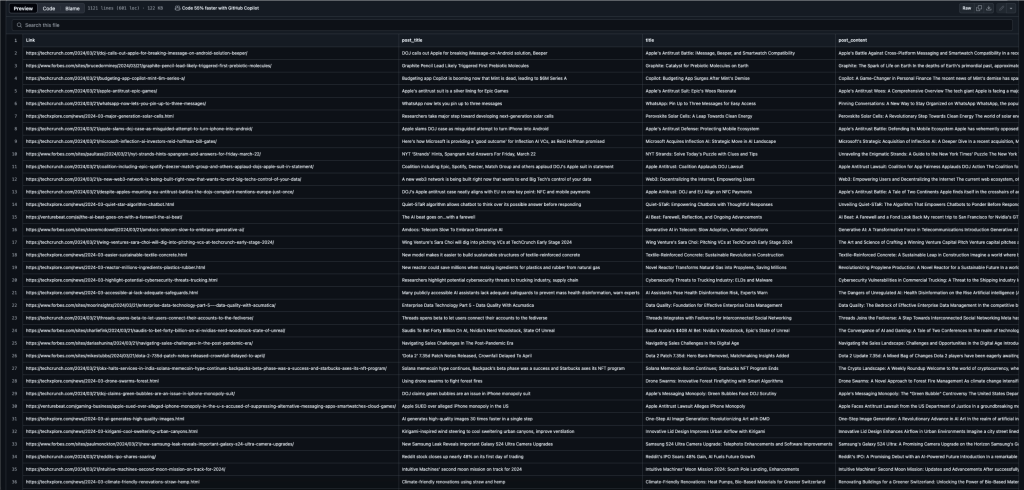
This Python project automates the process of scraping, processing, and publishing news content from major websites like Reuters, TechCrunch, Forbes, ZDNet, VentureBeat, Engadget, and TechXplore. The tool scrapes various data points, such as titles, content, images, and keywords, ensuring that all news items are at least 24 hours old and free of duplicates. Processed data is edited using GPT models for improved readability and SEO optimization before being uploaded to a WordPress website.